
Robust estimation
10/Aug 2016
Least squares optimization is a super useful technique, and indeed I’ve used it twice on this blog before.
However, it has a major down side - it’s very susceptible to pollution by outliers. In one of my previous posts using least squares optimization I used a technique called RANSAC to deal with outliers, today I want to talk about a different approach.
The issue with least squares
First, let’s recap the issue with least squares by working through a simple example. Let’s say we have a line like so: $$ y = mx + b $$
Let’s set $$ m=2 $$ and $$ b = 20 $$, yielding a line like so:

Now, let’s generate some points on this line with some added noise:

And then we can fit a new line to this jittered data using least squares optimization:

So far so good! This reconstructs a slope of 1.98 and an intercept of 19.92 which is extremely close to the real line.
However, watch what happens when we add just a few outliers and then try to reconstruct the line again:

As you can see, just four outliers was enough to severely skew the reconstructed line (in this case it finds a slope of 3.28 and an intercept of 13.24). If you think about it, this makes perfect sense. Least squares optimization minimizes the sum of the squares of the residuals, which means that the further away a data point gets from the model, the more influence it has. So outliers can have an extremely large impact on the final fitted model, just by virtue of having a very large square residual.
Robust estimation using M-estimators
The idea behind M-estimators is to modify the least squares cost function a bit. Instead of optimizing a function of the form: $$ "cost"(\beta) = sum_i r_i(\beta)^2 $$ , we instead optimize $$ "cost"(\beta) = sum_i \rho(r_i(\beta)) $$ . This function $$ \rho(x) $$ is some “loss function” that replaces the traditional squaring of the residuals with something that de-emphasizes outliers a bit.
Here are a few examples of common loss functions:

So as you can see, the $$ x^2 $$ function gets very large as the residual gets big, which explains the susceptibility to outliers of traditional least squares. However, the two other functions start off quadratic look but then smoothly transition into something flatter, which reduces the influence of outliers.
Solving M-estimators using iteratively reweighted least squares
To find the value of $$ \beta $$ that minimizes our new cost functions we could use an iterative non-linear optimization technique like gradient descent to directly optimize the cost functions above. However, it turns out there is a more efficient technique is called iteratively reweighted least squares.
The basic idea behind this algorithm is to repeatedly call a highly optimized least-squares solver with updated weights each time (e.g. a direct solver for linear least squares, or something like Levenberg-Marquardt for non-linear least squares). So all you need is a function that can optimize weighted least squares problem like the following:
$$ "cost"(\beta) = sum_i w_i r_i(\beta)^2 $$While there’s some cleverness involved in how to select these $$ w_i $$ weights, intuitively the algorithm is pretty straightforward:
- Initialize all the weights $$ w_i $$ to 1.
- Run the least squares optimization to find an guess at the solution.
- Recompute the weights based on how close a given data point is to the current guess. Data points that are further away get a lower weight, as they are assumed to be more likely to be outliers.
- Go to step 2 for some number of iterations.
So if you squint at this it makes perfect sense. You use the previous estimate of the solution to figure out which data points don’t fit the model well, then you de-prioritize those data points for the next iteration.
In order for this to be more than just something that makes sense intuitively, we have to carefully select the weights so that the iterative procedure above ultimately converges to the correct expression. I’m not going to dig too deeply into the process for deriving this (it’s not as hard as you might think), because in practice you should probably just use one of the following two:
$$
"huber"(r) = 1 \ \ \ if |r| < k
$$
$$
\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ = k/|r| if |r|>=k
$$
$$
"tukey"(r) = (1-(r/k)^2)^2 if |r| < k
$$
$$
\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ = 0 \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ if |r|>=k
$$
Both of these rely on a tunable constant $$ k $$, which controls where the “threshold” is for what’s considered an outlier. In order for these functions to work on any data set, this value should be set so that it relates to the standard deviation of the residuals (e.g. for data that varies less, you should have the “outlier region” start earlier, and vice versa).
Unfortunately, the standard deviation is also pretty susceptible to outliers so we instead use a robust estimate of the standard deviation for residuals (I’ve honestly forgotten where I first found this ridiculous equation, but as far as I can tell it originally comes from the book “Outliers in Statistical Data” by Barnett and Lewis):
$$
hat \sigma = 1.4826 * "median"_i |r_i|
$$
In other words, compute the median of the absolute values of the residuals, and multiply by a magic number. Once you have this robust standard deviation, the constant for Huber can be expressed as some factor on top. Experimentally, $$ 1.345 hat \sigma $$ have been found to well. For the Tukey biweight you might use $$ 4.6851 hat \sigma $$. These are magic numbers that seem to come up again and again.
Yeah, it’s a bit iffy to use these magic numbers, I agree. But feel free to tune them with impunity for your data. The key point is to find a cutoff point for your loss function so it tends to act more or less like a quadratic function on the inliers, and starts to trail off for the outliers.
So which one should you use? Huber or Tukey? I tend to prefer Huber because it’s a bit less extreme, which makes me less nervous. As data points start moving into the “outlier region” it simply switches to a linear cost instead of quadratic, which does make the outliers less influential, but without completely ignoring them (just in case they’re not actually outliers). If you don’t have a ton of outliers this will still typically be enough because the inliers will overwhelm this now-manageable influence from the outliers.
Tukey on the other hand completely stops increasing the cost of outliers after a certain point (as you can see from the fact that it sets the weight to zero for values further away than $$ k $$). This seems a bit extreme to me, just in case some of those points aren’t truly outliers. That said, if you’re fairly confident that Tukey won’t accidentally kill off inliers due to the way you’ve tuned your constant, it might give slightly better results.
Here’s an example of fitting the above noisy data, with outliers, using the Huber loss function, and the suggested magic numbers above:

Et voila! Problem solved. This finds a slope of 2.09 and an intercept of 19.36.
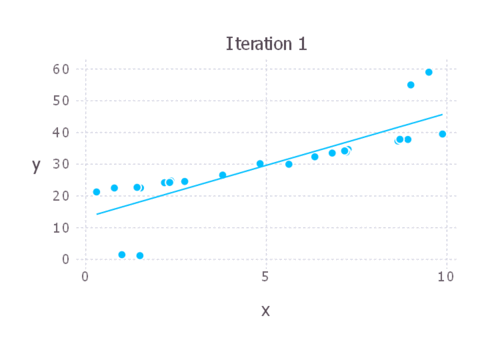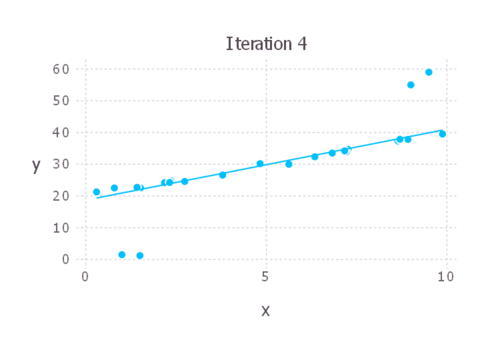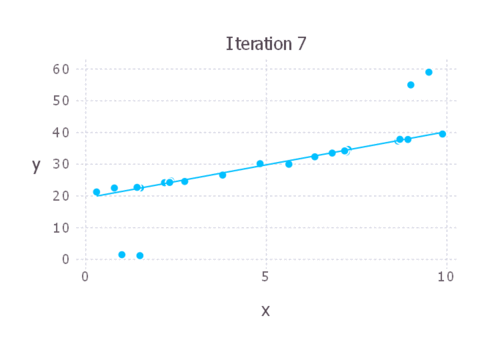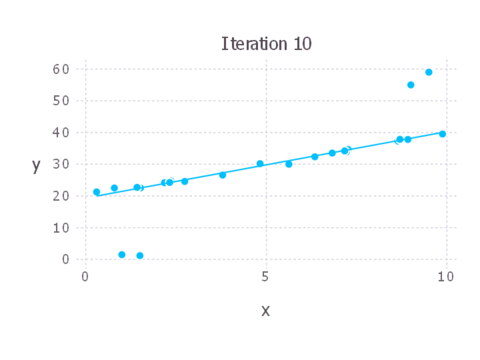
Here’s an animation showing each iteration of IRLS. As you can see, in this case the solution converges pretty quickly and we don’t need many iterations at all to end up with a good solution.
When to use M-estimators
On this blog I’ve previously used RANSAC to do robust estimation, which briefly works by picking a small subset of data points, hoping that they’re all inliers, fitting a model to it, and then using that to identify which of the other data points are also inliers. So should you use RANSAC or M-estimators? The short answer is that you should probably use RANSAC if you can.
There are, however, a number of cases whee RANSAC doesn’t work so well.
- If your inliers are extremely noisy, it may not be feasible to get a “good enough” model by selecting a small subset of them. I.e. you may never find a model from just a small subset that can be used to identify other inliers.
- If you have tons of parameters, then the number of data points you need to select to build a candidate solution will also be large. This makes it significantly less likely that you’re going to find a subset of all-inliers in a reasonable number of iterations.
- If it’s somehow hard or to find a random subset of the input data that can be used to build an approximate model then RANSAC may not be a good choice.
- If there’s no clear inlier/outlier distinction but you still want to gradually suppress the influence of extreme data points, then RANSAC can’t be used by definition.
- If you don’t like the somewhat random nature of RANSAC where you can’t really tell how many iterations are necessary to get a “hit”, then IRLS offers a more predictable choice. If you’re on a time budget, RANSAC might not give you sensible a solution at all in time allotted. Meanwhile the worst case scenario for M-estimators using a fixed number of IRLS iterations is that some tricky inputs don’t fully converge (but it’ll still be much better than plain least squares!)
One example of when you might not be able to use RANSAC is if you’re trying to approximate some complicated function with a model that isn’t very expressive (e.g. approximate a complicated surface using a bi-quadratic spline). In that case the data points that don’t fit with the model aren’t really outliers per se (so we don’t want to preemptively get rid of them completely, like RANSAC would), but in order to make the model fit “most” of the inputs well, we want to lessen the disproportionate influence that extreme values would normally have in least squares optimization.
Another example where RANSAC is hard to use is something like Bundle Adjustment where there’s just a ton of parameters and it’s not clear how to select a subset of the input data in order to produce a meaningful candidate solution.
Conclusion
Anyway, that’s it! M-estimators and IRLS are actually a relatively easy-to-use extension of least squares optimization that seems to be less widely known that they should be. Hopefully this post has helped show that using the basic technique isn’t actually all that much more complicated than the least squares optimization.